Today’s strongly-typed, object-oriented programming languages give you the tools you need to pick up a lot of errors at compile-time, before even one line of your code is executed. Using strong types effectively also enables you to write code that can easily be understood be someone else while placing little cognitive load on them. However, many programmers don’t take advantage of strong types and write code using generic data types instead of taylormade data structures. This code tends to be error-prone and hard to understand.
What’s the big deal?
Programming with strongly-typed variables and compile-type type checks has many benefits:
- it speeds up your development time: you don’t need to deploy and run your code to find many potential bugs
- it improves your code quality: type-safety means many mistakes are just not possible to make without a big compile error (or a red squiggly on the offending code in most modern IDEs)
- it makes your code more expressive, which is something your colleagues, or even yourself in 6 months, trying to understand your code will appreciate.
Settling for less
In a recent project I worked on, we needed to present documents to the user and group these by document type and year. Each group of documents could therefore be identified by the combination of document type (itself identified by a unique String identifier) and the year.
One method needed to produce a map of document type + year to a list of documents in that group, so a Map<..., List<Document>>.
Now let’s look at two suboptimal ways we could represent the keys in this map — a document type identifier and a year — and what the potential problems are with them before looking at how to do it in a type-safe way.
Using a String
Why this is a bad idea
There can be many good reasons to encode a tuple as a string: for example to be able to include it in a URL. Query parameters in a URL are really just tuples encoded as a String by joining the parameter name and the value with an = in between.
Encoding structured data as a String is acceptable in this case because the medium via which the data is transferred (i.e. a URL) does not support structure, only flat strings. However, if you receive such an encoded String in your object-oriented program, you should always decode it into a suitable structure as soon as you get it, and use the structure in your code. This will greatly improve readability of your code.
Using a String as a means to represent structured data in an object-oriented program is a bad idea: it hides the meaning of the elements of the data structure as all you can see is characters. Even worse, you now have some encoding logic that is usually not immediately evident from the code, e.g.
- what separator character are you using to separate the values?
- how are you escaping this separator character if it occurs in one of the values?
Finally, because String tend to be widely used in (Java) programs, it’s very easy for the String-encoded tuple to be accidentally switched with another String, for example when calling a method that takes two String arguments. The compiler will have no way of warning you because it just see the String type, not the fact that one of the String is really an encoded data structure.
Trying it anyway
Encoding a String document identifier and a year in a String could look like this in Java:
String documentTypeIdAndYear = "A1492,2021"This is essentially a CSV (Comma-Separated Values) representation of the tuple.
Problems would arise if the document type id contains a comma, since we’d have to devise some way of distinguishing a comma that’s a delimiter from a comma that’s part of a value.
Most importantly, when you just see String documentTypeIdAndYear, it’s impossible to tell how document type id and year are represented in that String: you’ll either need to look at the documentation of the method that accepts such a parameter (assuming it is documented), or look at where the method is being called and how the String is being produced there. In particularly poor code, you might have to go back several method calls to get to where the String was produced, if it is passed along several nested method calls!
The tuple as a Map key
String work well as Map keys since they implement equals and hashCode.
So for our document map example, when encoding the tuple as a String, we would have a Map<String, List<Document>>.
However, it’s important to note that a small difference in encoding the tuple into a String, such as adding a space after a comma delimiter, would result in a different key and different output from what you were expecting.
So remember: String is not a data structure; don’t use it that way!
Using an array, list, Map.Entry or tuple
Why this is a bad idea
Guava, a widely used Java library that extends Java with useful types and utility functions, rejected a proposal to add a Tuple (a data structure that could hold two arbitrary values) to their types. The reason they gave was this:
Tuple types are awful obfuscators. Tuples obfuscate what the fields actually mean (
Guava IdeaGraveyardgetFirstandgetSecondare almost completely meaningless), and anything known about the field values. Tuples obfuscate method signatures:ListMultimap<Route, Pair<Double, Double>>is much less readable thanListMultimap<Route, LatLong>.
Trying it anyway
Using a generic type like a tuple, an array or a list for our document type + year tuple might look like this in Java:
// Using an array
Object[] documentTypeIdAndYear =
new Object[] { "A1492", 2021 };
// Using a List
List<Object> documentTypeIdAndYear =
Arrays.asList("A1492", 2021);
// Using a Map.Entry (effectively a tuple)
Map.Entry<String, Integer> documentTypeIdAndYear =
com.google.common.collect.Maps.immutableEntry(
"A1492", 2021);The first two options — Object[] and List<Object> — are pretty much the same. The type is very generic and just by looking at the type (without the documentTypeIdAndYear variable name) you can’t tell
- that are exactly two values in the array / list
- what the order of the values in the list
- what the actual types of the values is (
StringandInteger) - what the values mean
The third option — Map.Entry<String, Integer> — at least shows the types of the values, and the order, but it’s still just a String and an Integer with no explicit meaning in the type: “key” and “value” don’t really tell you much.
The tuple as a Map key
If we were to use one of these “tuples” as the key of our documents map, we’d have to make sure it implements equals and hashCode meaningfully. Arrays don’t do that in Java, so that disqualifies the Object[] solution. This leaves the two others, which would give us either
Map<List<Object>, List<Document>>, or<Map<Map.Entry<String, Integer>, List<Document>>.
Yikes! They both look terrible! Imagine having to read code that uses these data types.
Using a dedicated data structure
A simple data class containing a String documentTypeId and an Integer year would look something like this in Java 7 and up:
public class DocumentTypeIdAndYear {
public final String documentTypeId;
public final Integer year;
public DocumentTypeIdAndYear(
String documentTypeId,
Integer year
) {
this.documentTypeId = documentTypeId;
this.year = year;
}
public boolean equals(Object other) {
if (!(other instanceof DocumentTypeIdAndYear)) {
return false;
}
DocumentTypeIdAndYear that =
(DocumentTypeIdAndYear) other;
return
Objects.equals(
this.documentTypeId,
that.documentTypeId
)
&&
Objects.equals(
this.year,
that.year
);
}
public int hashCode() {
return Objects.hash(documentTypeId, year);
}
}(Using Lombok, or the Java 14 record type, or the Kotlin data class) this class could be reduced to 4 or 5 lines, but I wanted to keep this to just standard legacy Java.)
The class has two fields and it is immediately obvious what they are and what type they are without having to search in the code where the DocumentTypeIdAndYear is being instantiated: a document type ID and a year. Compare that to the previous solutions where this wasn’t obvious just by looking at the type!
The tuple as a Map key
Since we’ve implemented equals and hashCode meaningfully, we can use DocumentTypeIdAndYear as key in our documents map: Map<DocumentTypeIdAndYear, List<Document>>. Again, it’s immediately clear that we’ve mapped our documents by document type ID and year and there’s no reason to go back to where the Map is instantiated and populated to understand what it represents.
Cognitive load
The main argument for using structured data types which we’ve emphasized in this article is that they make code easier to understand and follow: you don’t need to go back in the code to where the instance of a type is created to understand what it might contain.
This is incredibly important because, as a programmer, you are not just writing code that a machine can execute, no, you are writing something that should convey meaning and intention to other human beings that read it.
You have a responsibility to minimize the cognitive load on the reader. Cognitive load in psychology refers to the used amount of working memory resources (Wikipedia).
You can feel this cognitive load as it just feels more exhausting to read code that doesn’t use strong types: it’s harder to focus and it takes longer to make your way through the code than with code that takes advantage strong data types.
As a programmer, you are not just writing code that a machine can execute, no, you are writing something that should convey meaning and intention to other human beings that read it.
Minimizing this cognitive load means that anyone should be able to look at a section of your code, for example a method, and understand at a glance what it does, without needing knowing where the inputs came from.
If you use weak types, a reader often needs to go back and find the context in which the method is being called to understand what it does: in our example, to find out what this List<Object> is and what it would contain. This means you’re placing a higher cognitive load on the reader of your code because now they need to keep that information in working memory while looking at your method: “OK, remember, this List<Object> contains two items, the first is a String that is the document type identifier, the second is an Integer that is the document year.”
If, instead, you use a purpose-made, strong type, the type itself conveys its meaning and there’s no need to look up where the method is being called to understand it.
To put it another way: a weakly typed parameter creates a contract between the caller and the callee; a strongly typed parameter creates a contract between the caller and that type on the one hand, and the callee and that type on the other.
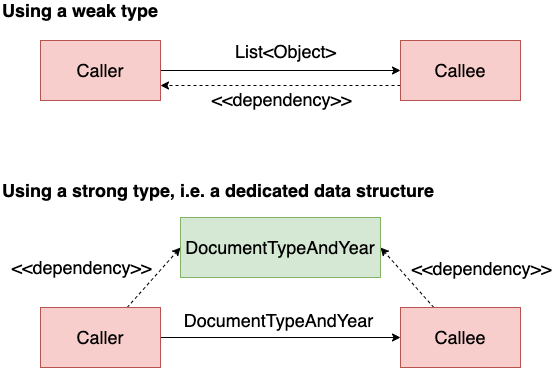
Because the data type is a very simple structure, that dependency is much more lightweight, and therefore easier to understand, than the dependency on the caller.
Other applications
This article focused on using dedicated types for representing a tuple. However, even a single value can warrant creating a dedicated type. Compare the following two methods on a fictional organization management program:
public addEmployee(String name, int age, String department);public addEmployee(Name name, Age age, Department department);At first glance, there doesn’t seem to be to much benefit in the second form; in fact, it would require constructing three objects (and first defining three classes) just to be able to call the method! So why is it “better”?
Let’s take the age parameter as an example. When using int, we could pass in any whole number from -2,147,483,648 to 2,147,483,647. But most of those are not realistic ages for an employee. OK, so we could change it to be a byte instead, which has a range of -128 to 128, but it would still allow you to pass in a negative age. By having a dedicated type, we can make sure that the value it holds is always a real age and this would be explicit in the method signature: the age parameter is not just any number, it’s an Age.
In other words: all ages are numbers, but not all numbers are ages.
Having a strongly-typed Age also means you could never mix up an age with another number, since they would literally be different types.
And similar arguments can be made for using a dedicated Name and Department types instead of Strings in this example.
Conclusion
Using dedicated structured data types instead of generic types like Strings, lists, and tuples can reduce the room for error in your code.
In addition, it reduces the cognitive load on whoever reads the code which makes it easier to understand and follow.
Dedicated types are not just useful for tuples: using them also introduce type-safety for single values such as “name” or “age”.

Have you wrestled with code that only uses weak types?
Do you consistently use strongly-typed data structures in your code?
Let us know by leaving a comment!